


Are Whales a Type of Fish?

This seems like a reasonable hypothesis for a child to make: Whales live in the water, they swim around, they’re vaguely fish-shaped, with a fish-like bulbous head, fishy fins and a fish-like tail.

Most adults in North America probably agree that whales are not a type of fish: they are a mammal. But why do we believe this? The honest answer is probably because we were told that whales are not fish. We were told this in school; we were told this in pop-sci television shows or YouTube videos; we have vague memories of scientists in white lab coats holding test tubes specifically telling us that whales are mammals; and heck, I bet if I went on Google right now and asked if a whale is a fish, the AI summary thing would tell me “No, it’s a mammal”.

So it’s settled, right? Everybody agrees that whales are not fish.
My long-time readers will know that I am a huge fan of linguistic descriptivism, which basically argues that if “everybody” “incorrectly” thinks a word means one thing, then actually, that word really does mean that thing now. So I can’t even wriggle my way out of this one via descriptivism: everybody agrees that whales are not fish. So, as per linguistic descriptivism, whales are not fish.
Okay, but are there maybe situations where linguistic descriptivism doesn’t apply?
I. Situations Where Linguistic Descriptivism Doesn’t apply
The foil to “linguistic descriptivism” is called “linguistic prescriptivism”. In a prescriptivist view, there are correct and incorrect usages of language, and whether a usage is correct is independent of the behaviors of the speakers of the language.
This view tends to ignore or even actively fight against the natural evolution of language.
For example, in English, the word “dog” is believed1 to have originally referred to a specific breed of dog, but is now used to refer to all different breeds of dogs more generally.

An English prescriptivist might argue that we are all using the word “dog” incorrectly here, except in the specific case where we are referring to that one specific breed that the word originally referred to. But, uh, which breed is that exactly? I don’t know, and probably the prescriptivist doesn’t know either. For all we know, maybe that breed is extinct or lost to time. But it doesn’t matter, what matters is that people on the internet are wrong and they need to be corrected.
(I’m only going to allow myself one xkcd comic per post, and I’m gonna save it for later, so just imagine the relevant xkcd comic in your head here.)
In contrast, a descriptivist might acknowledge that originally, the word “dog” referred to the breed “docga” and that what we today call “dog”, the English people at the time would have called “hound”. However, language evolves. The word “dog” underwent “semantic widening”, and is now used to refer to all sorts of hounds, rather than just specifically the docga hound.
The key mental model, the descriptivist argues, is that the English speaking community intends to refer to a certain abstract concept when they utter the word “dog”. The concept that the speaker intends and the concept that the listener interprets is basically the same. And when, empirically, there is this wide acceptance in the language community about the association between the word and the concept, then this is literally what the word “mean” means: The word “dog” means dog, because when you hear the word “dog”, you think of a dog.
It would be ridiculous, the descriptivist argues, to say that the usage of a word is incorrect when literally everybody uses it that way.
The situation where descriptivists are wrong and prescriptivists are right—or more charitably, the situation where I adopt a more prescriptivist view than my usual tendencies—is in technical specifications.
Over time, technology has become more sophisticated and complex, and especially since around the industrial revolution during the 1700s to 1800s, there was a move towards standardization. Prior to this era, if your wagon’s wheel broke, you could take your wagon to the wagon-repair-guy (the carpenter? I dunno), and he’d look at your wagon, look at the 3 other wheels that were still okay, and he could make you a new wheel that would more or less match the good ones (roughly same radius, roughly same thickness, etc.), and it would all just work.
Nowadays, if your car wheel breaks down, and you take it to the car-repair-guy, he’ll look at your car and say “Sorry, that’s a Honda. We only have the parts to repair Volvos here.”
The idea behind standardization was that every instance of a given component would be identical (within some specific tolerance) so that if the component broke down in your machine, rather than needing a person with the institutional knowledge about exactly how your machine was built or how it works, she just needs to know The Standard, and she can swap out the broken component with a working-but-otherwise-identical component.
The joke that reality played on us is that we have competing standards, so someone who learns the Volvo standard might not know the Honda standard and vice versa.

Anyway, the point is that in our post-industrial-revolution world, we have organizations and committees who get together and publish standards. These are prescriptive documents. They define what it means for something to be a USB device, or a PDF file, or an e-mail. It doesn’t matter if “everybody” uses the term “USB” to describe to a given device—if that device doesn’t adhere to the USB spec, then it is not a USB device.
But surely, there has never been a specification that everybody followed incorrectly, right?
II. A Specification That Everybody Followed Incorrectly
HTTP stands for “HyperText Transfer Protocol” and it’s basically the protocol (or “language”) that web browsers and web servers (more pedantically, “HTTP servers”) use to coordinate sending web pages (more pedantically, “HTML documents”) back and forth so you can see your cat memes. If you’re old enough to remember FTP, Usenet or, God forbid, Gopher, you’ll know that all of these are not HTTP servers. They used a different protocol. An FTP server (FTP stands for “File Transfer Protocol”) could still transfer an HTML document to you, but it wouldn’t be using the HTTP protocol to do so, and so there was a decent chance that your web browser wouldn’t be able to communicate with it.2 It’s like expecting all Asian people to be able to communicate with each other. No. Some Asian people speak Mandarin. Others speak Cantonese. Others speak Japanese. Others speak Korean. Some Asian people can speak multiple Asian languages, but I’m pretty sure no Asian person speaks “all Asian languages”. Two people can only communicate if they share some language in common.
Anyway, the concrete example I have for you is “HTTP/1.1”. That’s the name of a specific variant of the HTTP protocol (just like you have the umbrella term “USB”, and then you have specific protocols like “USB 2.1”, “USB 3.0”, etc.) As per the spec, all compliant HTTP/1.1 servers must support pipelining3. (For context, pipelining is supposed let you browse the internet faster by letting you request multiple documents at once up front).
Well, it turns out that no server supported pipelining.4 They tried to implement pipelining, but they all contained bugs that corrupted the response or introduced security issues (e.g. accidentally seeing a response intended for someone else, such as their password or account data). In the end, web browsers just never sent a pipeline request so as to never trigger the bug, and we all pretended that that feature didn’t exist.
This is a situation where there was a “prescribed” correct usage (a client can ask for documents X, Y and Z all up front, and the server should then fetch these documents and return them in order), but everybody did something else instead (oops, I accidentally slipped in document W in there, and also I gave you document Z before document Y). We don’t take the descriptivist viewpoint and say “Well, since all the web servers accidentally slip in document W, let’s just say that accidentally slipping in document W is actually a correct usage of the protocol.” Instead, we say “everybody is wrong.”5
Alright, fine, so in highly technical domains, it’s possible for a standard to emerge which defines things a certain way, and if “everybody” uses a different definition, they’re “wrong”. But so what? The scientific standard says that whales are mammals, not fish, so why even bring up this side argument?
III. The Scientific Standard Says That Whales Are Fish
The science that we all learn in school tends to be “a little wrong”. For example, we all learned Newtonian physics, right? F=MA, a body at rest tends to stay at rest, etc.? Well, it turns out that Newtonian physics is wrong. It’s wrong in the sense that we have a competing theory, called Einsteinian relativity. In many cases, Newton and Einstein give the same quantitative prediction for the motion of objects, and these predictions are “correct” (in the sense that when we carry out the experiment, the predictions match the results of the experiments). However, in scenarios where Newton and Einstein give different predictions, when we carry out the experiment, we consistently find out that Newton’s predictions are wrong and Einstein’s predictions are right.
So why do we bother teaching students “wrong” theories at all? There’s a two part answer to this.
The first part is: Because all theories are wrong. We also know that Einstein’s theory of relativity is wrong6, but we haven’t figured out a better theory yet. So just because a theory is “wrong” doesn’t preclude us from teaching it, or indeed for using it to accomplish real, productive work. We rely on Einsteinian relativity to perform GPS calculations so that the map app on your phone can pinpoint your location. It’s wrong, but it’s “good enough” for a lot of applications.
But then why don’t we just teach the “best” or “least wrong” theory that we currently know of?
That’s where the second part of the answer comes in: Because Newtonian physics is much simpler than Einsteinian relativity, and is “good enough” for a ton of situations.
You may be familiar with the term “rule of thumb” to refer to an approximation that’s good enough for most situations. The origin of that term refers to the fact that most adult’s thumbs are about an inch wide, so if you need to estimate the length of something that could reasonably be measured in inches, you can use your thumb as a guide.

Obviously, if you have a ruler handy and you really cared about accuracy, it’d be better to use a ruler than your thumb. But sometimes it’s inconvenient to go get a ruler, and sometimes, while you care about accuracy a little bit, you don’t care enough that the inconvenience of fetching a ruler outweighs the additional accuracy you would get.
And note that even rulers are wrong (in the sense that they’re not 100% accurate), and if you really cared about accuracy, you would use an inferometer instead, which tries to infer distances by having a laser reflect off of something so that it interferes with itself, which can give you information about where in its wavelength phase did the reflection happen. But also note that even inferometers are wrong (in the sense that they’re not 100% accurate), and if you really cared about accuracy, you would need to start using the principles of quantum physics to realize that objects don’t have a definite position in space and so the thing you’re trying to measure is incoherent anyway.
But again, for most situations, you don’t need that much accuracy. So just eye-balling it with your thumb is good enough. Your thumb fits a specific niche in the Pareto front balancing between accuracy and convenience.

This is a diagram of the Pareto front comparing “Accuracy” versus “Convenience”. The red dots presents things on the front. The point labeled B might represent the inferometer: Very accurate, but not very convenient. Point G might be your thumb: Very convenient, but not very accurate. Point H is the most convenient but least accurate. Maybe it represents the heuristic of “Just assume everything is exactly 1 meter long.” Point E is somewhere in between (middling accuracy, middling convenience) and might represent using a ruler.
There are also the grey points, which are not on the Pareto front. Point K is a grey point, and maybe it represents using a novelty rubber toy stretchy ruler. It’s less accurate and less convenient than point E, just using a normal ruler. So you would never want to use one of these grey points, because there’s something objectively better regardless of whether we’re prioritizing accuracy or convenience.
Both Newtonian physics and Einsteinian relativity lies on the front (so they’re worth using depending on the situation). And Newtonian physics is good enough for the vast majority of situations most adults will ever find themselves in. You’ll probably never need Einstein relativity just like you’ll probably never need an inferometer.
Most adults in North America learn a tiny bit about “biological taxonomy”, or more informally “classifying animals”. They learn that there exists a category called “mammal” and a different category called “fish” (and a bunch of other categories). They also learn that there are like “Kingdoms” and “Genus” and “Species”, but they might not remember the hierarchical order of which goes above which, or whether “mammal” is a “kingdom” or a “genus” or what.
Well, I have good news for most adults in North America: This biological taxonomy system is “wrong”, and it’s probably not even on the Pareto front (i.e. it’s a grey point, not a red point).
At the risk of being a little dismissive and unfair to taxonomists, historically, the way biological taxonomy was done was field researchers would “just look at” animals, and if they kinda looked the same, they would be placed into the same group. So under this system (sometimes called the “Linnaean” system), we’d come up with a group label like “reptile” and we’d defined it like “ectothermic and has scales”, and then we look at animals and see if they’re ectothermic and have scales, and if they do, we say it’s “a reptile”, and if they don’t, we say it’s “not a reptile”.
Since those early days, we’ve made a lot of improvements to the classification system, but we’ve run into a lot of conceptual roadblocks that hinted that the whole approach might need to be rethought from the ground up.7 For example, DNA analysis has revealed that a lot of things that we thought were related actually aren’t, and vice versa.
So instead, starting from the 1960s, an alternative system has been slowly gaining popularity, called “cladistics”. In cladistics, we acknowledge, and indeed focus on, the fact that every organism has at least one biological parent (except, I guess, the very first one—the cladistists have their own chicken and egg problem). A “clade”, then, is defined as the group of all organisms that descended from a specific ancestor.
By analogy, consider a family tree diagram.
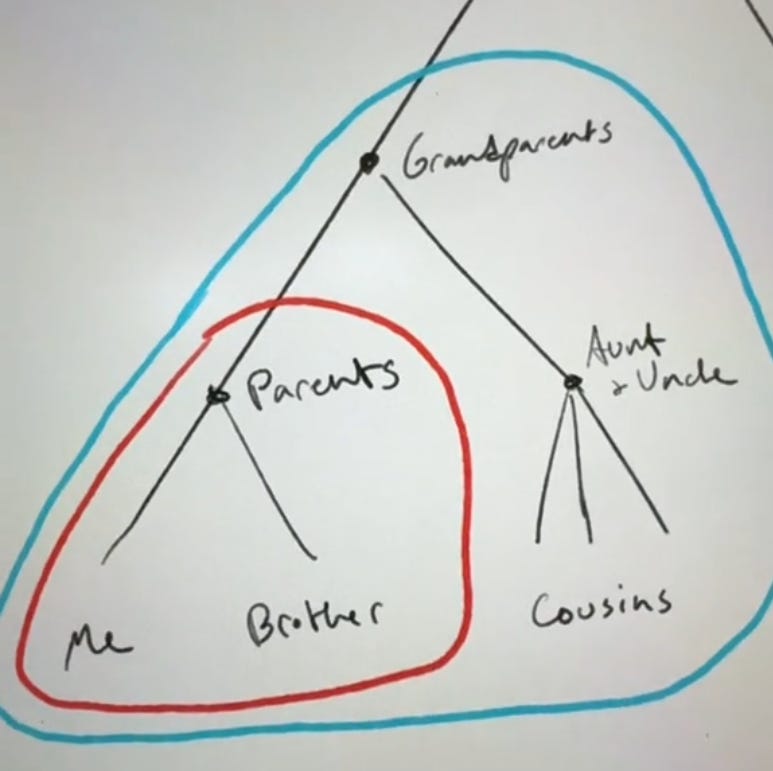
The red grouping represents one clade: my parents and all organisms that descended from my parents, which includes me and my brother. The blue grouping represents another clade: my grandparents and all organisms that descended from them. Note that the red clade is a part of the blue clade. This is a key difference from Linnaean taxonomy, that clades are constantly nested in each other. Cladistics is the accepted scientific consensus for the classification of organisms, at least according to Berkeley University.
Most adults in North America have the vague sense, via exposure to the pop-sci zeitgeist, that chickens are dinosaurs. But also, chickens are birds. And dinosaurs are reptiles. Under the Linnaean taxonomic system, it’s difficult to make sense of this.
In the cladistics system, we’re simply saying that chickens are part of the “bird” clade, and that the entire “bird” clade is part of the “dinosaur” clade (or more pedantically, the clade “Ares” descends from the clade “Dinosauria”), so yes chickens (and all birds) are also dinosaurs. And dinosaurs are reptiles (or more pedantically, the clade “Dinosauria” is part of the clade “Sauropsida”), which means chickens are also reptiles.
And similarly, we have the following nesting of clades:
Cetacea (whales, dolphins), which descended from…
Eutheria (placentals), which descended from…
Mammalia (mammals), which descended from…
Tetrapoda (four-limbed vertebrates), which descended from…
Sarcopterygii (lobe-finned fishes), which descended from…
Osteichthyes (bony fishes)
So yes, scientifically speaking, whales are fish.
IV. This is the Part Where I Backpedal
As a devoted descriptivist, I believe that the primary purpose of language is to communicate, and if you tell people that “whales are fish” without providing about three thousand words of context like I have here, you’ll probably cause more confusion than communication. So I do not advocate for claiming (or believing) that whales are fish.
Instead, the goal of this article was to explore the complexity that underlies a claim like “whales are (not) fish”, and the nature of labels (like “whales” and “fish”) and how they relate to the underlying reality. I want to promote a habit of thought where “whales are (not) fish” is not a fact that one can memorize and regurgitate, but rather a claim whose truth-value is dependent on how you operationalize the claim. E.g. is this a evolutionary claim about the ancestry of the organism? Or is it a morphological claim about whether they have lungs or gills? Or is it a sociological claim about how a randomly chosen person will answer a question?
There’s some dispute as to whether this specific “dog” example of semantic widening is historically accurate, but my argument doesn’t rely on this specific example. It just relies on the fact the semantic widening is a thing that sometimes happens, which is not in dispute.
Historically, there was a decent chance that your web browser could speak to the FTP server, because many web browsers were “multilingual” as per my later Asian analogy. That is, some web browsers of the time were designed so that they understood the HTTP protocol, the FTP protocol, and maybe a handful of others.
There’s some confusion online about what exactly this means, but I feel like if you read the original spec at https://datatracker.ietf.org/doc/html/rfc7230#section-6.3.2 it’s pretty clear: The spec says that a client “MAY ‘pipeline’ its requests”. Some internet commenters seem to have latched onto the word “MAY” and incorrectly concluded that that means the server doesn’t necessarily have to implement pipelining, or that it’s an optional feature of HTTP/1.1. That’s incorrect. The spec says that a client may (or may not) use pipelining. If the client might use pipelining, that means the server MUST support pipelining, because it must understand every valid message the client might send.
Imagine a spec for being able to communicate in English. A person MAY use the past tense when speaking to you. That doesn’t mean learning the past tense of verbs is optional: you MUST know how past tenses work if you want to be certified as an English speaker, but we can’t guarantee whether any given conversation you have with somebody will definitely involve a verb conjugated in the past tense.
Okay, sure, maybe there exists some web server out there that implemented it correctly. However, note that:
According to https://news.ycombinator.com/item?id=28083301, Apache, Nginx and IIS all did not implement it correctly (and that’s probably like at least 95% of the market share right there)
It was bad enough that browsers just decided to never send a pipeline request, because chances were very good that whatever server you were talking to would implement it incorrectly.
The feature has been superceded by HTTP/2, so there’s no motivation to make a new web server that does implement pipelining correctly, except to make this post become wrong.
That said, sometimes we do take the descriptivist approach. In the 1980s, IBM was the dominant personal computer manufacturer, and the implementation of their BIOS contained bugs. 3rd party manufacturers wanted to make so-called “IBM clones” which were computers compatible with IBM but cheaper. They had to copy those bugs so that if you bought software designed for IBM computers and then ran it on their clone computers, it would still work (since some software relied on the “incorrect” buggy behavior).
This is a case where we really did say (the equivalent of) “well, everybody accidentally slips in document W, so let’s just say that the correct behavior to do when we receive this request is to also slip in document W.”
Google for “conflict between relativity and quantum physics” if you want to find out more on this.
If you want to learn more about this, start from https://en.wikipedia.org/wiki/Species#The_species_problem and then google around from there.
A cartwright [is a person who repairs wagons and wagon wheels].
This essay did not go where I thought you were going to go!
It did make me measure my thumb, though (.75 of an inch, so basically a fish).
I was also surprised you didn't touch on the fact that fish don't exist. (Obviously, bony fishes exist, but "fish" is not a useful specialist concept, as it basically means "things that are usually under water, and look or move or otherwise function in ways that give 'fishy' vibes, rather than 'nonfishy' vibes, even though these things we call fish are not even remotely related", a definition which could absolutely include whales.)
Anyway, enjoyable read, and I especially liked the Pareto Front visualization!
(More random thoughts... do bacteria have a parent? Is that concept even applicable to them? Are you including viruses in your definition of biological organism? I love how complicated dividing stuff is. Have you read 'Every Living Thing' (about Linnaeus and Buffon) yet?)